con <- DBI::dbConnect(RPostgres::Postgres(),
dbname = Sys.getenv("AUG15_dbname"),
host = Sys.getenv("AUG15_host"),
user = Sys.getenv("AUG15_user"),
password = Sys.getenv("AUG15_password"),
port = Sys.getenv("AUG15_port"))I recently completed the PostgreSQL for Everybody specialization on Coursera from the University of Michigan.
This post builds on knowledge from the first two courses in the series, Database Design and Basic SQL in PostgreSQL and Intermediate PostgreSQL. I’ll demonstrate how to:
- Structure a CSV file into relational tables without vertical replication;
- Use the normalized database for some basic queries.
I previously collected India’s Independence day speeches for an R data package, and included it as a CSV file, and so I can use that for demonstration.
Make a Connection
The specialization focused on using psql or Python as the client to send commands to the PostgreSQL server. Here though I’ll use R as the client (and later pgAdmin).
Normalize a Database
The specialization discussed what it means to normalize a database, why that is important, and how to do it starting from a CSV file that has vertical replication of string data.
Create a raw table
My first step was to create an empty table in the database matching the schema of the CSV—with the addition of an “_id” integer column for every text column.
DROP TABLE IF EXISTS corpus_raw;
CREATE TABLE corpus_raw
(year INTEGER,
pm TEXT, pm_id INTEGER,
party TEXT, party_id INTEGER,
title TEXT, title_id INTEGER,
footnote TEXT, footnote_id INTEGER,
source TEXT, source_id INTEGER,
url TEXT, url_id INTEGER,
text TEXT, text_id INTEGER);Copy CSV file into the raw table
Once I made the empty raw table, I copied in the data from the CSV file with psql.
-- wget https://raw.githubusercontent.com/seanangio/aug15/main/inst/final_csv/corpus.csv
\copy corpus_raw (year, pm, party, title, footnote, source, url, text) FROM 'corpus.csv' WITH DELIMITER ',' CSV HEADER;Handle missing data
Before doing anything though, I want to handle the missing data values.
R codes missing data as NA, and so when I copied the CSV file into PostgreSQL tables it imported these values as the string “NA”. SQL though represents missing values with the value NULL, and so I should recode tables with missing values accordingly.
UPDATE corpus_raw
SET title = (CASE WHEN title = 'NA' THEN NULL ELSE title END),
footnote = (CASE WHEN footnote = 'NA' THEN NULL ELSE footnote END),
source = (CASE WHEN source = 'NA' THEN NULL ELSE source END),
url = (CASE WHEN url = 'NA' THEN NULL ELSE url END),
text = (CASE WHEN text = 'NA' THEN NULL ELSE text END);Now with null values representing all of the missing data, I can continue.
Insert distinct data into separate tables
From the raw table, I then extracted the distinct data for every text column into its own table. This let me store exactly one copy of every string.
DROP TABLE IF EXISTS party CASCADE;
CREATE TABLE party (
id SERIAL,
name VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
);
INSERT INTO party (name)
SELECT DISTINCT party
FROM corpus_raw
ORDER BY party;
DROP TABLE IF EXISTS pm CASCADE;
CREATE TABLE pm (
id SERIAL,
name VARCHAR(128),
PRIMARY KEY(id)
);
INSERT INTO pm (name)
SELECT DISTINCT pm
FROM corpus_raw
ORDER BY pm;
DROP TABLE IF EXISTS title CASCADE;
CREATE TABLE title (
id SERIAL,
title VARCHAR(128),
PRIMARY KEY(id)
);
INSERT INTO title (title)
SELECT DISTINCT title
FROM corpus_raw
ORDER BY title;
DROP TABLE IF EXISTS footnote CASCADE;
CREATE TABLE footnote (
id SERIAL,
footnote VARCHAR(1056),
PRIMARY KEY(id)
);
INSERT INTO footnote (footnote)
SELECT DISTINCT footnote
FROM corpus_raw
ORDER BY footnote;
DROP TABLE IF EXISTS source CASCADE;
CREATE TABLE source (
id SERIAL,
source VARCHAR(1056),
PRIMARY KEY(id)
);
INSERT INTO source (source)
SELECT DISTINCT source
FROM corpus_raw
ORDER BY source;
DROP TABLE IF EXISTS url CASCADE;
CREATE TABLE url (
id SERIAL,
url VARCHAR(1056),
PRIMARY KEY(id)
);
INSERT INTO url (url)
SELECT DISTINCT url
FROM corpus_raw
ORDER BY url;
DROP TABLE IF EXISTS text CASCADE;
CREATE TABLE text (
id SERIAL,
speech TEXT,
PRIMARY KEY(id)
);
INSERT INTO text (speech)
SELECT DISTINCT text
FROM corpus_raw
ORDER BY text;Now every table, such as party below, has an integer ID for every unique string, which is stored in the database only once.
SELECT * FROM party;| id | name |
|---|---|
| 1 | BJP |
| 2 | INC |
| 3 | Janata Dal |
| 4 | Janata Party |
Update the raw table
I then inserted these integer keys into the raw table.
UPDATE corpus_raw SET party_id = (SELECT party.id FROM party WHERE party.name = corpus_raw.party);
UPDATE corpus_raw SET pm_id = (SELECT pm.id FROM pm WHERE pm.name = corpus_raw.pm);
UPDATE corpus_raw SET title_id = (SELECT title.id FROM title WHERE title.title = corpus_raw.title);
UPDATE corpus_raw SET footnote_id = (SELECT footnote.id FROM footnote
WHERE footnote.footnote = corpus_raw.footnote);
UPDATE corpus_raw SET source_id = (SELECT source.id FROM source WHERE source.source = corpus_raw.source);
UPDATE corpus_raw SET url_id = (SELECT url.id FROM url WHERE url.url = corpus_raw.url);
UPDATE corpus_raw SET text_id = (SELECT text.id FROM text WHERE text.speech = corpus_raw.text);Make a new table of only foreign keys
I then made a copy of the raw table, removed the redundant text columns, and added the foreign key constraints.
-- copy to a new table
DROP TABLE IF EXISTS corpus;
CREATE TABLE corpus AS
TABLE corpus_raw;
-- drop un-normalized redundant text columns
ALTER TABLE corpus
DROP COLUMN party,
DROP COLUMN pm,
DROP COLUMN title,
DROP COLUMN footnote,
DROP COLUMN source,
DROP COLUMN url,
DROP COLUMN text;
-- add foreign key constraints
ALTER TABLE corpus
ADD CONSTRAINT fk_pm
FOREIGN KEY (pm_id)
REFERENCES pm (id);
ALTER TABLE corpus
ADD CONSTRAINT fk_party
FOREIGN KEY (party_id)
REFERENCES party (id);
ALTER TABLE corpus
ADD CONSTRAINT fk_title
FOREIGN KEY (title_id)
REFERENCES title (id);
ALTER TABLE corpus
ADD CONSTRAINT fk_footnote
FOREIGN KEY (footnote_id)
REFERENCES footnote (id);
ALTER TABLE corpus
ADD CONSTRAINT fk_source
FOREIGN KEY (source_id)
REFERENCES source (id);
ALTER TABLE corpus
ADD CONSTRAINT fk_url
FOREIGN KEY (url_id)
REFERENCES url (id);
ALTER TABLE corpus
ADD CONSTRAINT fk_text
FOREIGN KEY (text_id)
REFERENCES text (id);Create an entity-relationship diagram
I also loaded all of this into pgAdmin as one easy way to create an ERD.
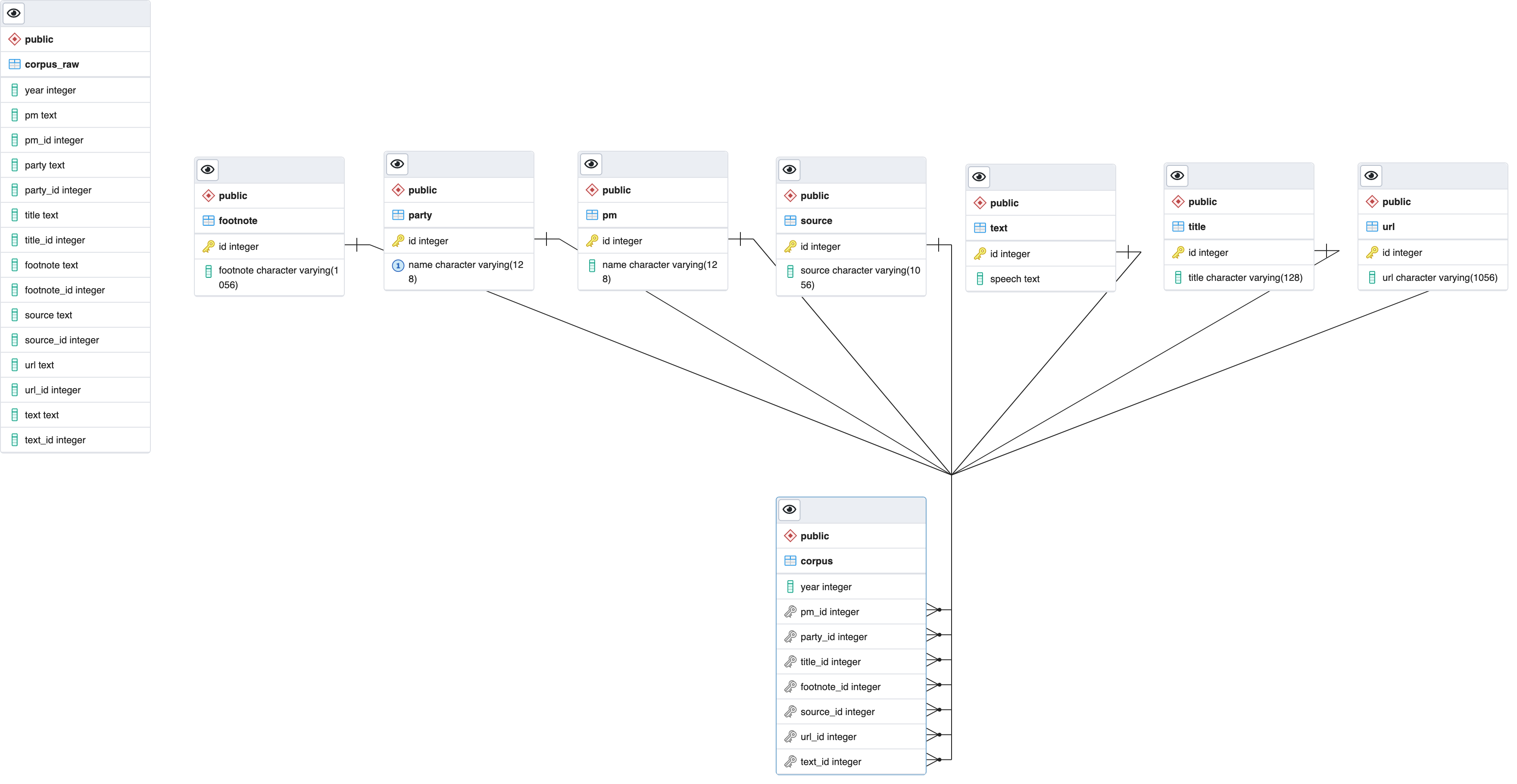
Test some queries
My last step was to confirm the results with some test queries. The new corpus table has only integer columns (which refer to strings in other tables).
SELECT * FROM corpus ORDER BY year LIMIT 5;| year | pm_id | party_id | title_id | footnote_id | source_id | url_id | text_id |
|---|---|---|---|---|---|---|---|
| 1947 | 6 | 2 | 11 | 2 | 3 | NA | 18 |
| 1948 | 6 | 2 | 39 | 3 | 3 | NA | 17 |
| 1949 | 6 | 2 | 43 | 63 | 4 | NA | 53 |
| 1950 | 6 | 2 | 44 | 59 | 23 | 17 | 54 |
| 1951 | 6 | 2 | 13 | 57 | 24 | 18 | 20 |
I can recreate the original table through a series of joins. For example, I can find which prime ministers have given the most speeches.
SELECT pm.name AS pm,
party.name AS party,
COUNT(*) AS speech_count
FROM corpus
JOIN pm ON corpus.pm_id = pm.id
JOIN party ON corpus.party_id = party.id
GROUP BY pm.name, party.name
ORDER BY COUNT(*) DESC
LIMIT 10;| pm | party | speech_count |
|---|---|---|
| Jawaharlal Nehru | INC | 17 |
| Indira Gandhi | INC | 16 |
| Narendra Modi | BJP | 10 |
| Manmohan Singh | INC | 10 |
| A.B. Vajpayee | BJP | 6 |
| P.V. Narasimha Rao | INC | 5 |
| Rajiv Gandhi | INC | 5 |
| Morarji Desai | Janata Party | 2 |
| L.B. Shastri | INC | 2 |
| I.K. Gujral | Janata Dal | 1 |
*(This assumes though Nehru gave a speech in 1962, which I’ve never found evidence of having taken place).
The focus of the specialization was not writing SQL itself, but it did show some techniques, such as for working with dates and casting columns. For example, I calculated the number of days since every speech.
SELECT year,
EXTRACT(DAY FROM (
NOW() - (year || '-08-15')::date
)) AS days_since_speech
FROM corpus
ORDER BY year DESC
LIMIT 5;| year | days_since_speech |
|---|---|
| 2023 | 438 |
| 2022 | 803 |
| 2021 | 1168 |
| 2020 | 1533 |
| 2019 | 1899 |
Wrap-up
And so although a simple example, those are the basics of database design!
In future posts, I’ll use the same database to explore other topics in the specialization, such as regular expressions, indexes, and JSON.